
What is Data Science?
Data Science is an interdisciplinary field involving the use of scientific methods, processes, and systems to collect, prepare and analyze data in the structured and unstructured form. Data science makes use of various fields including mathematics, statistics, databases, information science and computer science. The data can be of many types and of various sizes.
Need for Data Science as a separate field:
The main reason for upgrading data science to the level of a separate field is the exponentially growing rate of data around us. Estimates show that around 1.7 megabytes of data will be produced per second by 2020. Digital data accumulation will reach 44 trillion gigabytes. With such large amounts of data, making sense of it and storing it becomes increasingly difficult. As a result, we require a way to study and make sense of this data. Hence Data Science was recognized as a separate field.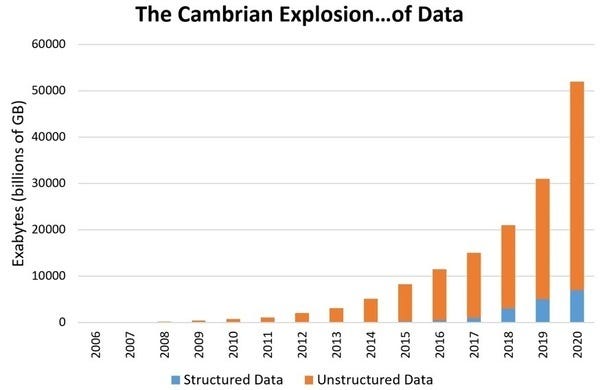
Data Science around us:
Companies are using data science to understand and easily sort their data processes within the company. For example, Google uses Data Science to personalize the advertisements displayed to users on the websites they use. This is done through their program AdSense which allows publishers to serve content to targeted audiences.
Similarly, Uber calculates how much a customer is to be charged, when to give discounts and to whom. Airbnb helps people by estimating the price they should rent their homes for by using Data Science. In simple term, we can understand this by thinking of customers and users as raw data and data science helps to interpret that data.
Data Science in Government & Non- government organizations:
Data is a critical asset for government organizations. There is an increasing amount of data collected every day. Hence they require a way to sort and store all this data, which can be done through Data Science. Similarly, non-government organizations also use data science. The WWF uses data sciences to show information in a statistical matter regarding wildlife issues and hence make their cause effective.
Opportunities in Data Science:
As the field of data science continues to grow, job opportunities in this field are also increasing exponentially. Analysis done by LinkedIn on data science job growth showed a large increase in the field of data science, especially in the past 30 years. If you are interested in data science, you can get free courses online. Check out this tutorial on a Common lounge.

Key Components:
Now we will give you some insight into data science and its various components.
1: Programming:
Data Science is all about data. To organize and analyze this data we use programming. Programming languages are of many types. The two most widespread being Python and R.
Python: Python is the most readable and flexible programming language, hence its widespread use. It has many powerful statistical and numerical packages including NumPy and pandas, Matplotlib, Tensorflow, iPython etc. Python is much faster and easier to learn.
R: R is another programming language but most of it is focused on statistical and graphical techniques. R is widely used among statisticians and data miners for developing statistical software and data analysis. It is an open source language.
2: Data and its types:
The next key component is the data itself. In order to understand data, we must first understand its types.
Structured Data: Structured data refers to information with a high degree of organization. It can be easily represented in tabular form, can be stored and processed in databases.
Unstructured data: Unstructured data is information that does not have a data model or is not organized. It may consist of text or data such as dates, numbers, emails, PDF files, images, videos etc.
Natural Language: Data in the form of written languages used to communicate such as English, Spanish, and Urdu etc. It can be considered as a sub-type of unstructured data.
Image, Video, Audio: Images, videos, and audios are also unstructured in form. They are generated using cameras and microphones. The increasing use is seen in smartphones where images and videos are saved and processed every day.
Graph-based Data: Graph is a set of vertices and edges. It is a mathematical structure used to show the relationship between two entities.
Machine Generated: Machine-generated data is created by computer systems, applications or machines without the involvement of humans.
3: Statistics, Probability and its relation to Data Science:
Statistics: Statistics is a branch of mathematics which deals with the collection, interpretation, analysis, presentation, and organization of data. It uses pro0gamming ti analyze data.
Probability: Probability is the measure of the likelihood of an event to occur. It is quantified as a number between 0 and 1, where 0 indicates impossibility and 1 indicates certainty.
Relation to Data Science: Statistics and probability both are related to data science. They are the foundation of processing and analyzing data. We use both these sciences in relation with data science to interpret data correctly.
4: Machine Learning:
Machine learning is the field of computer science stemming from AI. It uses statistical techniques to give computers the ability to learn without being programmed. The machine progressively improves its performance on a specific task by changing the structure or program. There are three main goals of machine learning. One, to learn the changes and representation of these changes. Second, to generalize the performance, so it is effective not on a single task but on similar tasks alike. Third. To improve the performance of a machine and find ways to prevent degrading performance. In data science, machine learning is used in algorithms, regression and classification methods. It is used to predict the outcome from data being processed in different ways.
5: Big Data:
Big Data is the name given to data is such a large quantity that storing or processing this data requires a large number of computers. It is characterized by three Vs:
Volume: Data in large volumes ranging from terabytes to zettabytes.
Variety: Data can show a lot of variety and diversity. It can be a mixture of two or more types of data, for example, structured and unstructured both.
Velocity: Data is being generated at a constantly growing rate. Essentially it is the speed of data.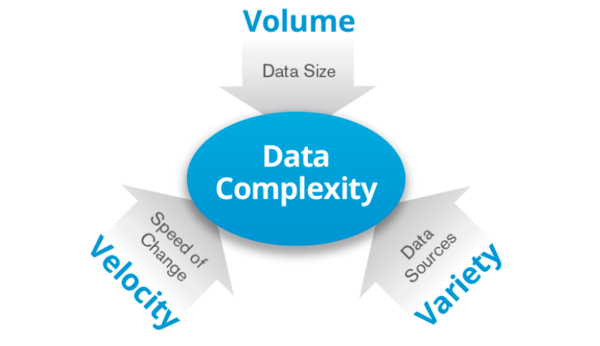
In data science, data is grouped into many forms and types. Big data can be referred to humongous volumes of data which cannot be processed by using traditional applications. Data scientists use different tools to study and process big data, for example, Hadoop, Spark, R, and Java etc.